人類算力天花板?1750 億參數的AI 模型GPT-3 引爆矽谷
這幾天轟動矽谷的 GPT-3 是什麼來頭?
相信不太了解AI 的朋友這幾天也或多或少看到了一些關於GPT-3 的重磅消息,甚至有媒體稱其為“繼比特幣之後又一個轟動全球的現象級新技術”。
請注意,現在站在你面前的是:互聯網原子彈,人工智能界的卡麗熙,算力吞噬者,黃仁勳的新KPI ,下崗工人製造機,幼年期的天網—— 最先進的AI 語言模型GPT-3。

1750 億參數組成的訓練模型
言歸正傳,OpenAI的研究人員在上個月發表了一篇論文,描述了GPT-3的開發,正式發布了這個由1750億個參數組成的AI語言模型。
在NLP 領域中,通常採用ELMo 算法的思想,即通過在大量的語料上預訓練語言模型,然後再將預訓練好的模型遷移到具體的下游NLP任務,從而提高模型的能力。GPT 模型是OpenAI 在2018 年提出的一種新的ELMo 算法模型,該模型在預訓練模型的基礎上,只需要做一些微調即可直接遷移到各種NLP 任務中,因此具有很強的業務遷移能力。
GPT 模型主要包含兩個階段。第一個階段,先利用大量未標註的語料預訓練一個語言模型,接著,在第二個階段對預訓練好的語言模型進行微改,將其遷移到各種有監督的NLP 任務,並對參數進行fine-tuning。
簡而言之,在算法固定的情況下,預訓練模型使用的訓練材料越多,則訓練好的模型任務完成準確率也就越高。
那麼1750 億是什麼概念?曾有人開玩笑說,“要想提高AI 的準確率,讓它把所有的測試數據都記下來不就行了?” 沒想到如今真有人奔著這個目標去做了……
在GPT-3 之前,最大的AI 語言模型是微軟在今年2 月推出的Turing NLG,當時擁有170 億參數的Turing NLG 已經標榜是第二名Megatron-LM 的兩倍。沒錯,僅短短5 個月的時間,GPT-3 就將頭號玩家的參數提高了10 倍!Nivdia 的黃老闆看了看年初剛畫的產品算力曲線,發現事情並不簡單。
OpenAI 曾於2019 年初發布GPT-2,這一基於Transformer 的大型語言模型共包含15 億參數、在一個800 萬網頁數據集上訓練而成,這在當時就已經引起了不小的轟動。整個2019 年,GPT-2 都是NLP 界最耀眼的明星之一,與BERT、Transformer XL、XLNet 等大型自然語言處理模型輪番在各大自然語言處理任務排行榜上刷新最佳紀錄。而GPT-2 得益於其穩定、優異的性能在業界獨領風騷。
而GPT-3 的參數量足足是GPT-2 的116 倍,實現了對整個2019 年的所有大型自然語言處理模型的降維打擊。
算力殺手
GPT-3 的論文長達72 頁,作者多達31 人。來自OpenAI、約翰霍普金斯大學的Dario Amodei 等研究人員證明了在GPT-3 中,對於所有任務,模型無需進行任何梯度更新或微調,而僅通過與模型的文本交互指定任務和少量示例即可獲得很好的效果。
GPT-3 在許多NLP 數據集上均具有出色的性能,包括翻譯、問答和文本填空任務,這還包括一些需要即時推理或領域適應的任務,例如給一句話中的單詞替換成同義詞,或執行3 位數的數學運算。
當然,GPT-3 也可以生成新聞報導,普通人很難將其生成的新聞報導與人類寫的區分開來。是不是細思極恐?
通常來說,自然語言處理任務的範圍從生成新聞報導到語言翻譯,再到回答標準化的測試問題。那麼訓練這個龐然大物需要消耗多少資源呢?
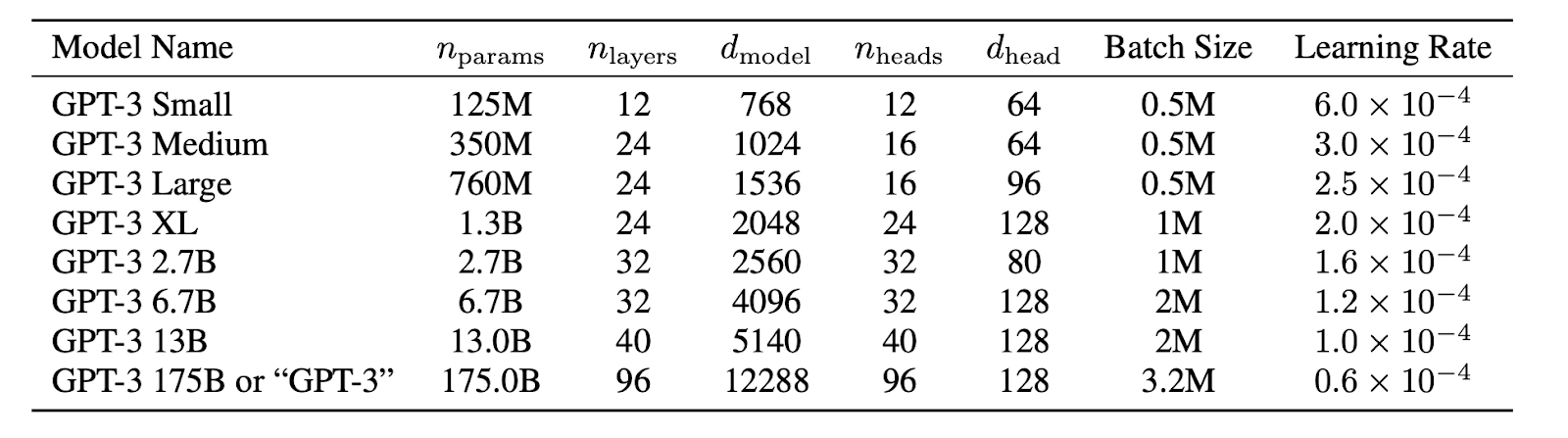
OpenAI方面表示: “我們在cuDNN加速的PyTorch深度學習框架上訓練所有AI模型。每個模型的精確架構參數都是基於GPU的模型佈局中的計算效率和負載平衡來選擇的。所有模型都在微軟提供的高帶寬集群中的 NVIDIA V100 GPU 上進行訓練。”
根據微軟早前公佈的信息,我們發現微軟給OpenAI提供的這台超級計算機是一個統一的系統,該系統擁有超過285000個CPU核心,10000個GPU和每秒400G的網絡,是一台排名全球前5的超級計算機。

GPT-3就是在微軟這霸道的“無限算力”加持下誕生的,據悉其訓練成本約為1200萬美元。
有什麼用?
既然訓練GPT-3 需要如此苛刻的超級環境,民間的什麼2080 Ti、線程撕裂者等家用級設備自然都是弟弟,那麼我們普通用戶要怎麼來用這個玩意兒呢?
目前,OpenAI 開放了少量GPT-3 的API 測試資格,商業公司、研究學者和個人開發者都可以申請,獲得資格的用戶可以通過遠程調用的方式體驗GPT-3 的強大。當然,這個資格並不容易拿到……
在國外,“ 拿到GPT-3 測試資格” 已經成為了一個“炫富”的新梗……
當然也有早期成功搶到測試資格的用戶。因為GPT-3 是一個史無前例的龐大語言模型,所以幾乎所有可以用文字表達的工作它都能勝任,你可以指導它回答問題、寫文章、寫詩歌、甚至寫代碼。
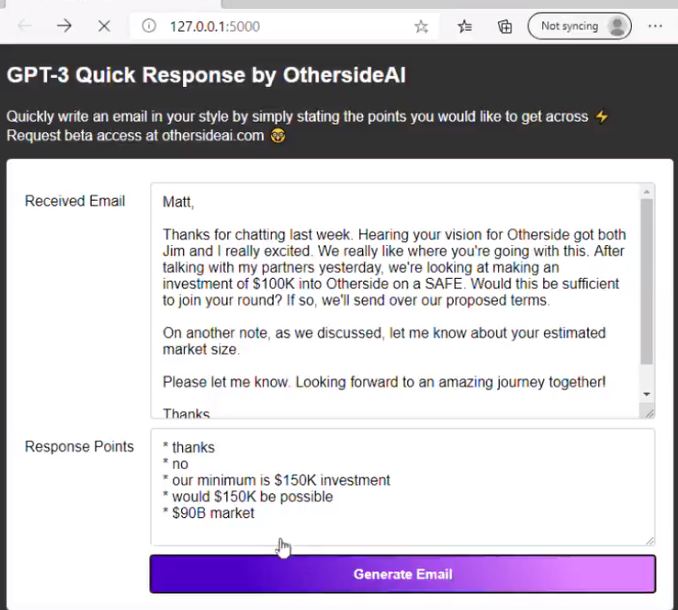
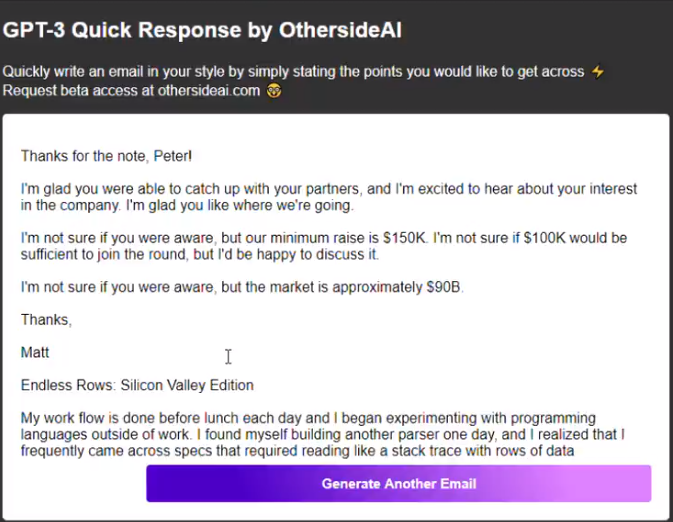
首先來看最基本的語言表達功能,下面是網友用GPT-3 開發的自動回覆郵件工具,只需要輸入幾個簡要的回復關鍵詞,GPT-3 就能自動生成一篇文筆流暢的回复郵件:
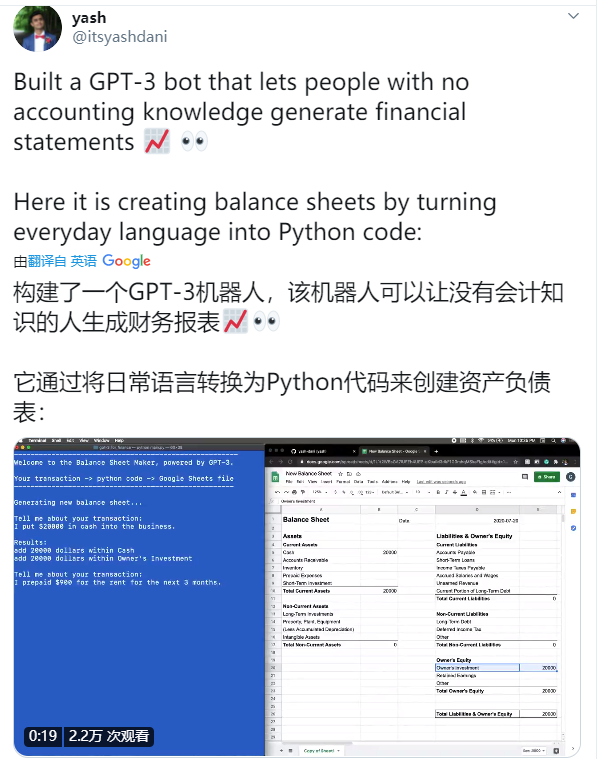
更深入一些,下面這位名叫yash 的網友用GPT-3 開發了一個Python 驅動的財務報表,它可以將日常語言轉換成Python 代碼來創建資產負載表:輸入“我今天投入了兩萬美元” 、“後三個月的房租預付了900 美元”這樣的自然語言,程序就能自動修改資產負債表上相應的項目數值。
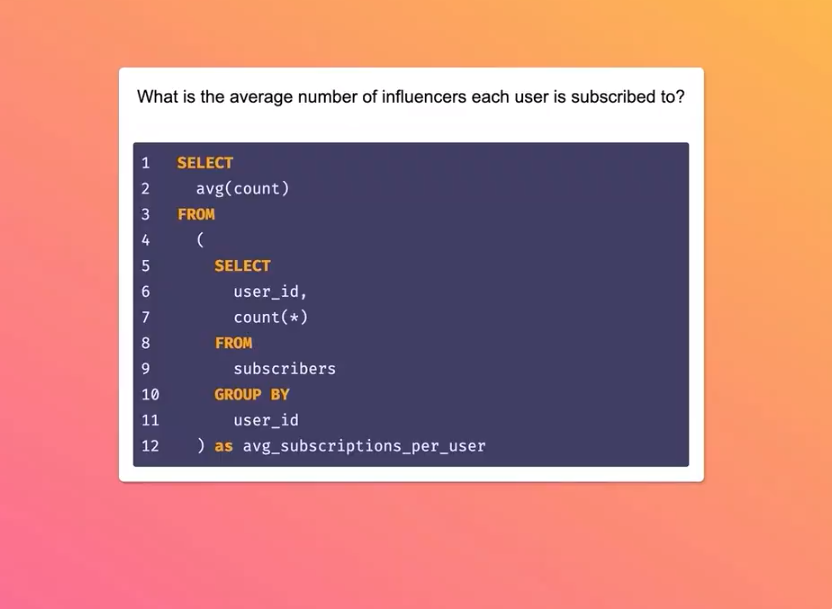
網友Faraar Nishtar 調用GPT-3 寫了一個小工具,能直接輸入自然文字生成他想要的SQL 查詢代碼:
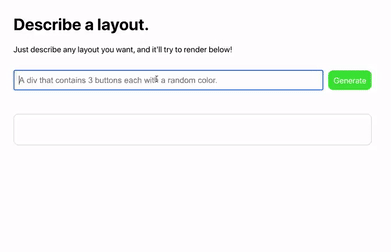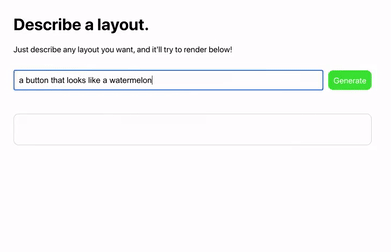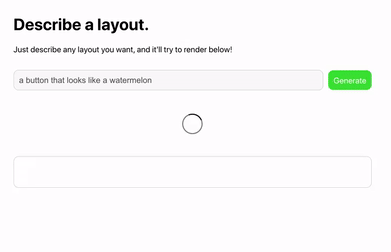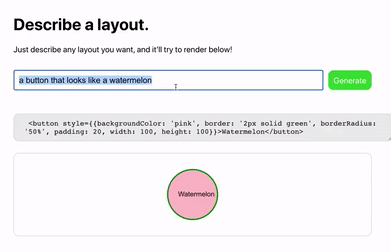
網友Sharif Shameem 開發出了一個新產品Debuild。這是一個調用了GPT-3 API 的網頁app 快速生成器,在輸入框裡用自然語言進行描述,它就可以快速輸出你想要的用戶界面,比如輸入“生成一個像西瓜一樣的按鈕”:
對於產品經理或前端設計師,只需要在設計軟件Figma 中加入GPT-3 插件,就可以打字生成你想要的前端效果:

也有開發者給GPT-3 做了圖靈測試,結果發現它的回答很有意思:

“如果在十年前用同樣的問題做測試,我會認為答題者一定是人。現在,我們不能再以為AI 回答不了常識性的問題了。”
古人云,“熟讀唐詩三百首,不會作詩也會吟。” 從人類歷史到軟件代碼,龐大的GPT-3 模型囊括了互聯網中很大一部分用文字記錄下來的人類文明,這些記錄造就了其強大的文字任務處理能力。
AI 語言模型參數量級近年來呈指數倍發展,隨著在摩爾定律下人類設備算力的提升,在未來的某一天,或許真的將會出現一個無限接近熟讀人類歷史所有文明記錄的超級模型,屆時是否會誕生出一個真正的人工智能呢?

最後引用神經網絡之父、圖靈獎獲得者Geoffrey Hinton 早前對GPT-3 的一番評論:
“ 鑑於GPT-3 在未來的驚人前景,可以得出結論:生命、宇宙和萬物的答案,就只是4.398 萬億個參數而已。”
本站文章除註明轉載外,均為本站原創或編譯。歡迎任何形式的轉載,但請務必註明出處,尊重他人勞動共創開源社區。轉載請註明:文章轉載自OSCHINA社區[http://www.oschina.net]本文標題:人類算力天花板?1750億參數的AI模型GPT-3引爆矽谷