Facebook 開源 NLP 建模框架 PyText,從研究到生產變得更容易
Facebook AI Research(FAIR) 開源了 NLP 建模框架 PyText 。
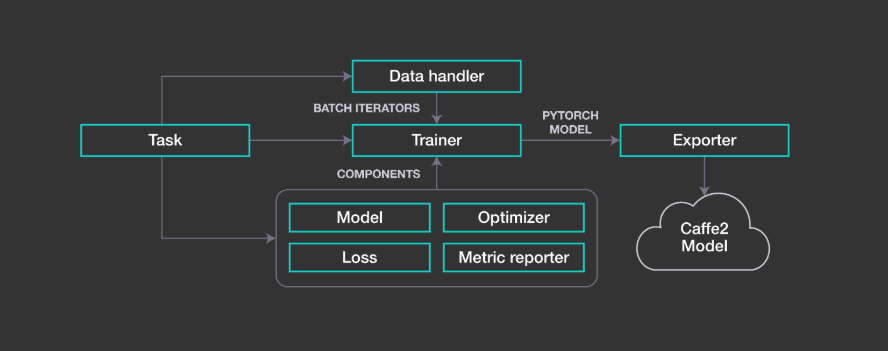
PyText 是一個基於 PyTorch 構建的深度學習 NLP 建模框架。PyText 通過為模型組件提供簡單且可擴展的接口和抽象,以及使用 PyTorch 的 Caffe2 執行引擎導出模型進行推理的功能,模糊了實驗與大規模部署之間的界限。其預訓練模型包括文本分類、序列標註等。
PyTorch 是一個統一的框架,縮短了從研究到生產的路徑,而基於 PyTorch 的 PyText 則著眼於滿足 NLP 建模的特定需求。
核心特性:
適用於各種 NLP/NLU 任務的生產就緒模型
- 文本分類
- 序列標註
- 聯合意圖時隙模型(Joint intent-slot model)
- 上下文意圖-時隙模型(Contextual intent-slot models)
支持在 PyTorch 1.0 中基於新 C10d 後端構建的分佈式訓練
可擴展組件,可輕鬆創建新模型和任務
參考實現和預訓練模型論文: Gupta et al. (2018): Semantic Parsing for Task Oriented Dialog using Hierarchical Representations
支持聯合訓練
項目地址:https://github.com/facebookresearch/pytext
瞭解更多:https://code.fb.com/ai-research/pytext-open-source-nlp-framework/
本站文章除註明轉載外,均為本站原創或編譯。歡迎任何形式的轉載,但請務必註明出處,尊重他人勞動共創開源社區。轉載請註明:文章轉載自 開源中國社區 [https://www.oschina.net]本文標題:Facebook 開源 NLP 建模框架 PyText,從研究到生產變得更容易